五分钟技术趣谈 | GET3D生成模型浅析
2023-08-31 08:15:28 来源: 《无敌破坏王2》)得益于2D生成模型在高分辨率图像合成中已经获得了逼真的质量,这一进展也启发了3D内容生成的研究。早期的方法旨在将2D CNN生成器直接扩展到3D体素网格,但3D卷积的高内存占用和计算复杂性阻碍了高分辨率下的生成过程。作为一种替代方案,其他研究已经探索了点云、隐式或八叉树表示。然而,这些工作主要集中在生成几何体上,而忽略外观。它们的输出表示也需要进行后处理,使其与标准图形引擎相兼容。为了能够实际应用到内容制作中,理想的3D生成模型应当满足以下要求:(a)有能力生成具有几何细节和任意拓扑的形状。(b)输出的应该是纹理网格,这是Blender和Maya等标准图形软件所使用的主要表达。(c)可以利用2D图像进行监督,因为它们比明确的3D形状更广泛。Part 023D生成模型简介为了便于内容创建过程并能够实际得到应用,能够产生高质量和多样化3D资产的生成性3D网络最近已经成为活跃的研究领域。每年都会有许多3D生成模型发表于ICCV、NeurlPS、ICML等大会,其中前沿的模型有以下几种:Textured3DGAN:作为卷积生成纹理3D网格方法的延伸,是能够在二维监督下,学习使用GAN从实物图像中生成纹理网格的一种生成模型。相较于以前的方法,放宽了姿态估计步骤中对关键点的要求,并将该方法推广到未标记的图像集合和新的类别/数据集,如ImageNet。DIB-R:底层由PyTorch机器学习框架构建的一种基于插值的可微分渲染器,已经被添加到3D深度学习的PyTorch GitHub库中(Kaolin)。该方法允许对图像中的所有像素的梯度进行分析计算,核心是将前景光栅化视为局部属性的加权插值,将背景光栅化视为由全局几何体的基于距离的聚合,从而学会了从单个图像预测形状,纹理和光线。PolyGen:使用基于Transformer的架构依次预测网格顶点和面的一种直接对网格建模的自回归生成模型。通过ShapeNet Core V2数据集进行训练,得到的模型已经十分接近于人类构建的结果。SurfGen:具有显式表面鉴别器的对抗性3D形状合成。通过端到端训练的模型能够生成具有不同拓扑的高保真3D形状。GET3D:从图像学习的高质量3D纹理形状的生成模型。核心是通过可微分表面建模、可微分渲染以及2D生成对抗性网络,可以从2D图像集合中训练模型,直接生成具有复杂拓扑、丰富几何细节和高保真纹理的显式纹理3D网格。图片
近年来,随着以Midjourney和Stable Diffusion为代表的AI图像生成工具的兴起,2D AIGC技术已经作为辅助工具被许多设计师运用到实际的项目工作中,在各类显性的商业场景中落地,创造越来越多的现实价值。同时随着元宇宙热潮的到来,许多行业正朝着创建大规模3D虚拟世界的方向发展,多样化、高质量的3D内容对一些行业正变得越来越重要,包括游戏、机器人、建筑和社交平台等。但是,手动创建3D资源非常耗时且需要特定的艺术素养以及建模技能。主要的挑战之一是规模——尽管可以在3D市场上找到大量的3D模型,在游戏或电影中填充一群看起来都不一样的角色或建筑仍然需要耗费艺术家大量的时间。因此,对能够在3D内容的数量、质量和多样性方面进行扩展的内容制作工具的需求也变得越来越明显。
图片
 【资料图】
【资料图】
图1 元宇宙空间(来源:《无敌破坏王2》)
得益于2D生成模型在高分辨率图像合成中已经获得了逼真的质量,这一进展也启发了3D内容生成的研究。早期的方法旨在将2D CNN生成器直接扩展到3D体素网格,但3D卷积的高内存占用和计算复杂性阻碍了高分辨率下的生成过程。作为一种替代方案,其他研究已经探索了点云、隐式或八叉树表示。然而,这些工作主要集中在生成几何体上,而忽略外观。它们的输出表示也需要进行后处理,使其与标准图形引擎相兼容。
为了能够实际应用到内容制作中,理想的3D生成模型应当满足以下要求:
(a)有能力生成具有几何细节和任意拓扑的形状。
(b)输出的应该是纹理网格,这是Blender和Maya等标准图形软件所使用的主要表达。
(c)可以利用2D图像进行监督,因为它们比明确的3D形状更广泛。
Part 023D生成模型简介为了便于内容创建过程并能够实际得到应用,能够产生高质量和多样化3D资产的生成性3D网络最近已经成为活跃的研究领域。每年都会有许多3D生成模型发表于ICCV、NeurlPS、ICML等大会,其中前沿的模型有以下几种:
Textured3DGAN:作为卷积生成纹理3D网格方法的延伸,是能够在二维监督下,学习使用GAN从实物图像中生成纹理网格的一种生成模型。相较于以前的方法,放宽了姿态估计步骤中对关键点的要求,并将该方法推广到未标记的图像集合和新的类别/数据集,如ImageNet。
DIB-R:底层由PyTorch机器学习框架构建的一种基于插值的可微分渲染器,已经被添加到3D深度学习的PyTorch GitHub库中(Kaolin)。该方法允许对图像中的所有像素的梯度进行分析计算,核心是将前景光栅化视为局部属性的加权插值,将背景光栅化视为由全局几何体的基于距离的聚合,从而学会了从单个图像预测形状,纹理和光线。
PolyGen:使用基于Transformer的架构依次预测网格顶点和面的一种直接对网格建模的自回归生成模型。通过ShapeNet Core V2数据集进行训练,得到的模型已经十分接近于人类构建的结果。
SurfGen:具有显式表面鉴别器的对抗性3D形状合成。通过端到端训练的模型能够生成具有不同拓扑的高保真3D形状。
GET3D:从图像学习的高质量3D纹理形状的生成模型。核心是通过可微分表面建模、可微分渲染以及2D生成对抗性网络,可以从2D图像集合中训练模型,直接生成具有复杂拓扑、丰富几何细节和高保真纹理的显式纹理3D网格。
图片
图2 GET3D生成模型(来源:GET3D论文官网https://nv-tlabs.github.io/GET3D/)
作为最近提出来的3D生成模型,GET3D通过ShapeNet、Turbosquid和Renderpeople中多个具有复杂几何图形的类别,如椅子、摩托车、汽车、人物和建筑,展示了在无限制生成3D形状方面的最先进性能。
Part 03GET3D的架构和特性图片
图3 GET3D架构(来源:GET3D论文官网https://nv-tlabs.github.io/GET3D/)
通过两个潜在编码生成了一个3D SDF(Signed Distance Field/有向距离场)和一个纹理场(Texture Field),再利用DMTet(Deep Marching Tetrahedra)从SDF中提取3D表面网格,并在表面点云查询纹理场以获取颜色。整个过程使用在2D图像上定义的对抗性损失来进行训练。特别是,RGB图像和轮廓是使用基于光栅化的可微分渲染器来获取的。最后使用两个2D鉴别器,每个鉴别器分别针对RGB图像和轮廓,来分辨输入是真的还是假的。整个模型是端到端可训练的。
除了以显式网格作为输出表达,GET3D在其他方面也非常灵活,可以很容易地适应其他任务,包括:
实现几何体和纹理的分离:模型在几何和纹理之间实现了很好的解耦,并且对几何潜在代码和纹理潜在代码都可以进行有意义的插值。
不同类别形状之间生成平滑过渡:通过在潜在空间中应用随机行走,并生成相应的3D形状。
生成新的形状:通过添加一个小噪声来扰动局部的潜在代码,可以生成看起来相似但局部略有差异的形状。
无监督材质生成:与DIBR++相结合,以完全无监督的方式生成材质并产生有意义的视图相关照明效果。
以文本为导向的形状生成:结合StyleGAN NADA,通过计算渲染的2D图像和用户提供的文本上的定向CLIP损失来微调3D生成器,用户可以通过文本提示生成大量有意义的形状。
图片
图4 基于文本生成形状(来源:GET3D论文官网https://nv-tlabs.github.io/GET3D/)
Part 04总结虽然GET3D朝着实用的3D纹理形状的3D生成模型迈出了重要一步,但它仍有一些局限性。特别是,在训练过程中,仍然依赖2D剪影以及相机分布的知识。因此,GET3D目前仅根据合成数据进行评估。一个有前景的扩展是可以利用实例分割和相机姿态估计方面的进步来缓解这个问题,并将GET3D扩展到真实世界的数据。GET3D也按类别进行训练,未来将扩展到多个类别,可以更好地表示类别间的多样性。希望这项研究能让人们离使用人工智能进行3D内容的自由创作更近一步。


热点推荐
-

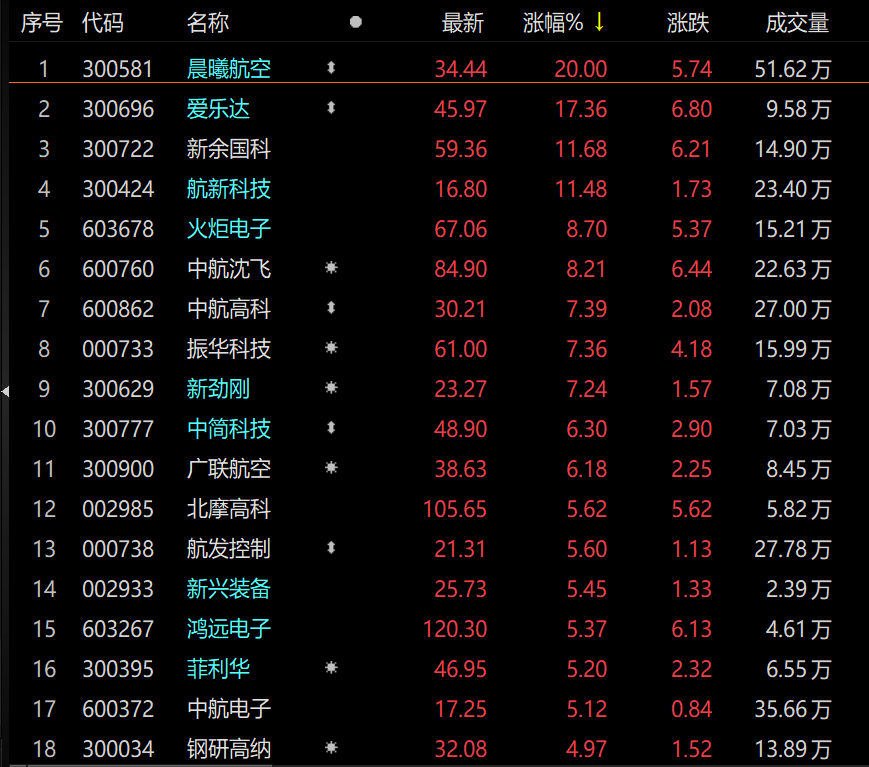
工龄与退休后工资领取对照表 工龄30年能领多少退休金?
-
嘉凯城(000918.SZ)今日起临时停牌 复牌时间未知
-
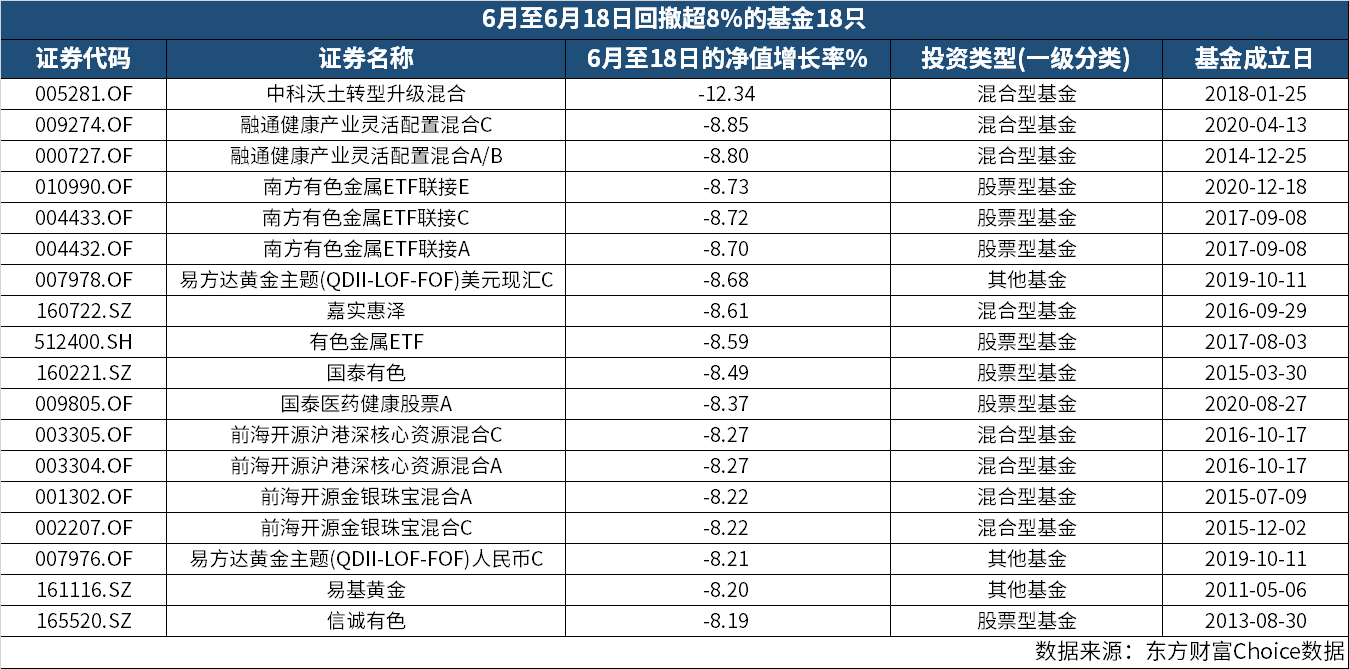
中科沃土转型升级混合 6月回撤已超12%
-
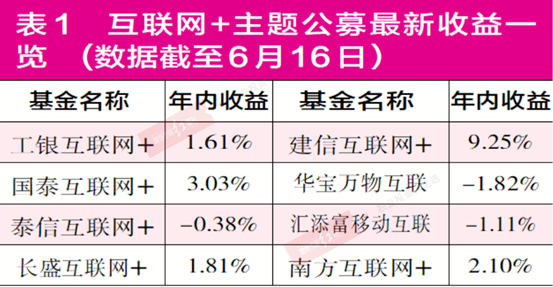
“互联网+”产品普遍举步维艰 多家产品被“深套”
-
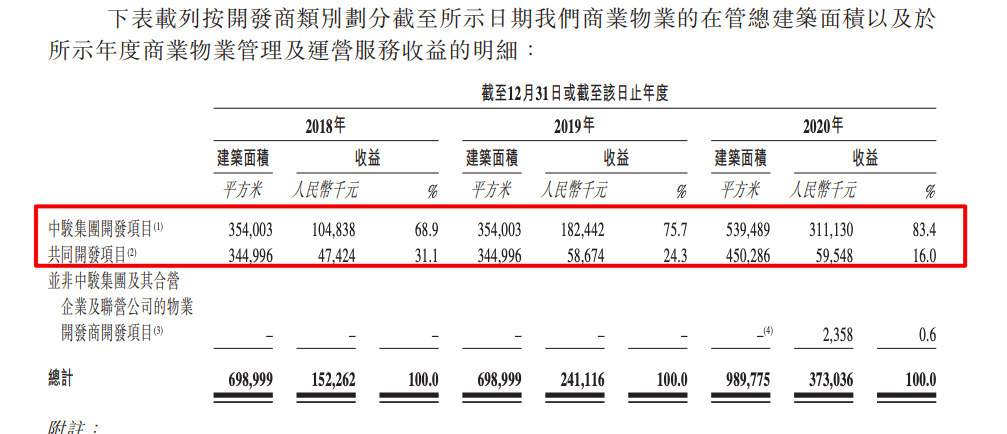
中骏商管将挂牌 中骏控股集团持股62.43%
-
五分钟技术趣谈 | GET3D生成模型浅析
-

中集集团上半年营收606亿 聚焦可持续有质增长
-

四季看新疆第二季沿着河湖看新疆主题采访活动启动
-

陕州区20个项目列入第九期“三个一批”项目
-

本年度最大满月!“超级蓝月亮”今夜登场
-

景业名邦上半年营收3.26亿元 归母净亏损3.77亿元
-

邻水县“五抓”举措强化高温天气执勤执法安全防护
-

山东海化:公司制盐原料来自地下卤水而不是海水,生产的原盐用于公司纯碱的生产
-

江西宜黄:“法律明白人”成为群众身边解忧人
-

数根光缆掉落悬挂空中,威海交警雨中化身“托举哥”
-

【问政面对面】承德市对脱贫人口和防止返贫检测对象是否有一次性交通补助?有答案了!
-

西安银行(600928.SH):上半年净利润13.33亿元,同比增长8.60%
-

中国GPU落后美国10年?科大讯飞:华为GPU已对标英伟达A100
-

万达电影上半年实现扭亏市占率近17% 影视院线公司业绩普增
-

封神第一部票房破24亿 基本情况讲解
-

浙江世宝:公司为新能源商用车及新能源乘用车提供不同的智能电动转向解决方案
-

财经头条:北向资金净流出势头放缓 增量政策预期升温
-

青岛市教育局:开展调研确保开学平稳顺利
-

多纳全屋定制_比纳全屋定制
-

提供岗位500多个!清河区举行暑期返乡高校毕业生专场招聘会
-
浙江余姚市泗门镇钢结构建筑倒塌事件被困人员已搜救完毕
-

甘肃白银继续发布干旱橙色预警 部分地区继续重度干旱
-

德邦证券给予九阳股份增持评级,九阳股份23H1点评:外销明显回暖,Q2收入同比转正
-

吉利吉利缤瑞COOL冠军版上市 售价8.18万元
-

cad2007以管理员身份运行打不开_运行打不开