ChatGLM2-6B 发布:8-32k 上下文,推理提速 42% 环球观点
2023-06-26 21:02:05 来源: OSCHINA
GLM 技术团队宣布再次升级 ChatGLM-6B,发布 ChatGLM2-6B。ChatGLM-6B 于 3 月 14 日发布,截至 6 月 24 日在 Huggingface 上的下载量已经超过 300w。
截至 6 月 25 日,ChatGLM2 模型在主要评估 LLM 模型中文能力的 C-Eval 榜单中以 71.1 的分数位居 Rank 0;ChatGLM2-6B 模型则以 51.7 的分数位居 Rank 6,是榜单上排名最高的开源模型。
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
 (资料图片仅供参考)
(资料图片仅供参考)
评测结果
以下为 ChatGLM2-6B 模型在 MMLU (英文)、C-Eval(中文)、GSM8K(数学)、BBH(英文) 上的测评结果。
推理性能
ChatGLM2-6B 使用了 Multi-Query Attention,提高了生成速度。生成 2000 个字符的平均速度对比如下
Multi-Query Attention 同时也降低了生成过程中 KV Cache 的显存占用,此外,ChatGLM2-6B 采用 Causal Mask 进行对话训练,连续对话时可复用前面轮次的 KV Cache,进一步优化了显存占用。因此,使用 6GB 显存的显卡进行 INT4 量化的推理时,初代的 ChatGLM-6B 模型最多能够生成 1119 个字符就会提示显存耗尽,而 ChatGLM2-6B 能够生成至少 8192 个字符。
项目团队也测试了量化对模型性能的影响。结果表明,量化对模型性能的影响在可接受范围内。
示例对比
相比于初代模型,ChatGLM2-6B 多个维度的能力都取得了提升,以下是一些对比示例。
数理逻辑
知识推理
长文档理解


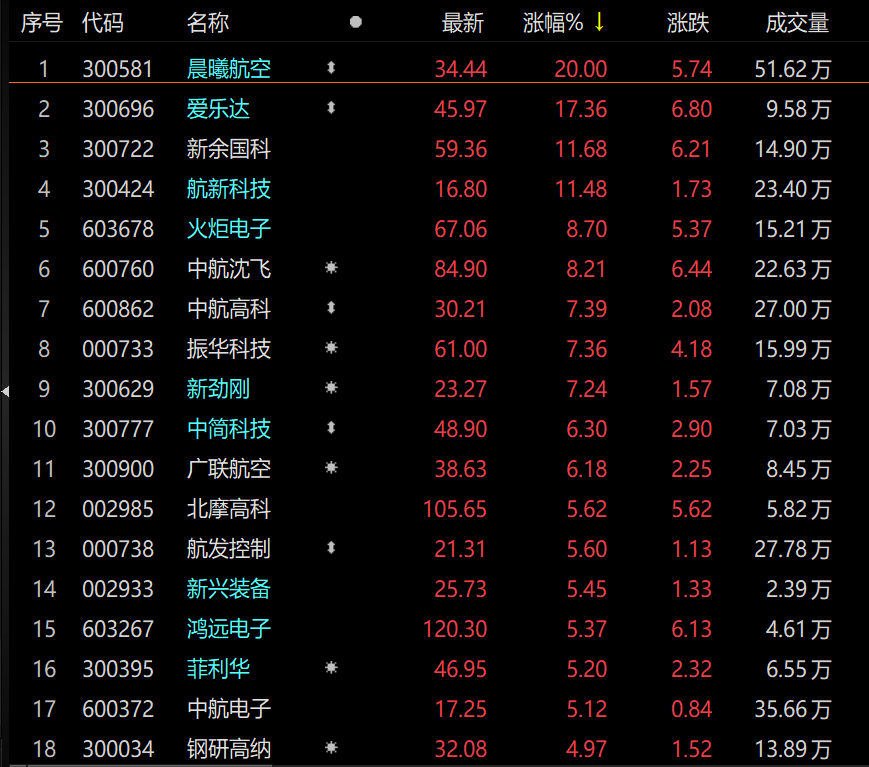
热点推荐
-

工龄与退休后工资领取对照表 工龄30年能领多少退休金?
-
嘉凯城(000918.SZ)今日起临时停牌 复牌时间未知
-
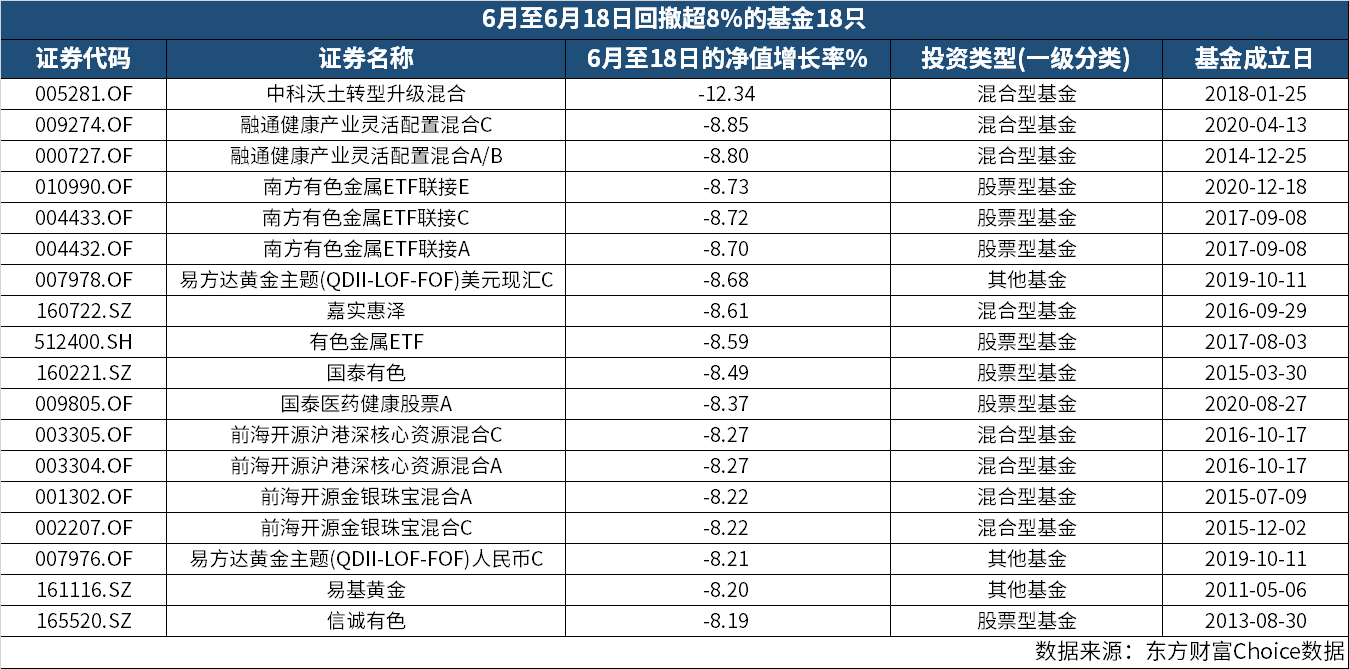
中科沃土转型升级混合 6月回撤已超12%
-
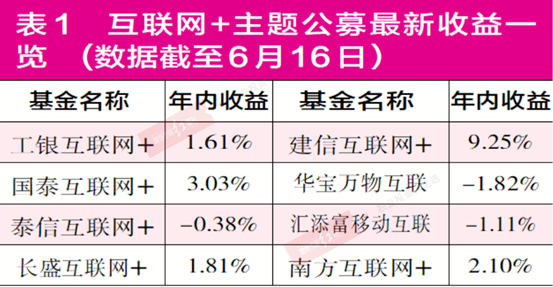
“互联网+”产品普遍举步维艰 多家产品被“深套”
-
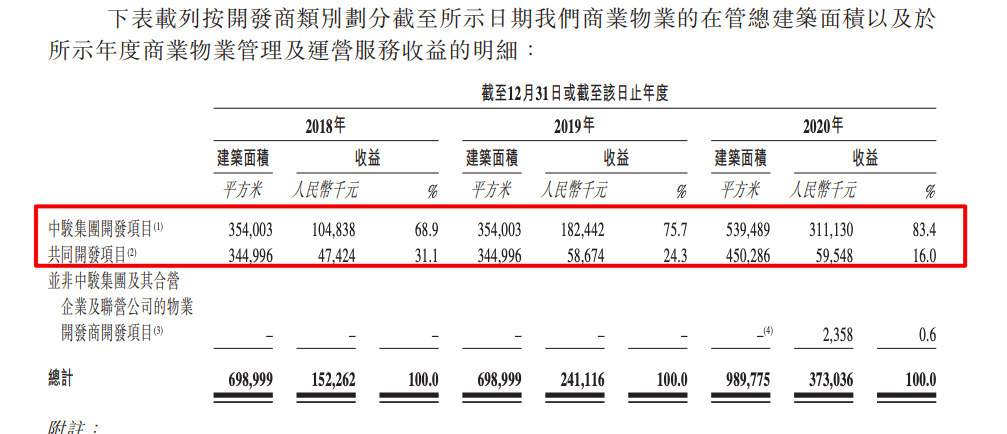
中骏商管将挂牌 中骏控股集团持股62.43%
-
ChatGLM2-6B 发布:8-32k 上下文,推理提速 42% 环球观点
-

“深圳一大厦异响振动”,官方最新通报:连续37天监测未见异常!房屋基础薄弱,将全面加固
-

新华全媒+|贵州“村超”的“超级周末”
-

赵镇藩的抗战人生和沈阳的解放(赵镇藩)-世界今日讯
-

存货大增计提却下降,160亿龙头调节利润? 当前热文
-

世界微动态丨石家庄财经职业学院2023年暑期社会实践正式启动
-

香港鲗鱼涌华厦工业大厦突取消强拍太古已收购余下单位|天天新动态
-

《永乐大典》“苏字册”原件首次“下江南”-环球最新
-

《青海西秦岭地区金属矿床成矿规律与找矿预测》出版 播报
-
“怀小稻”人社微课第63期|申领失业保险金有时间和次数限制吗?|全球短讯
-

中方敦促:立即释放! 当前最新
-

在家庭中角色的错位最容易引发悲剧
-

环球今热点:即将收获一员内线悍将!76人预计将会签下塞尔维亚内线新星?
-

天天简讯:该怎样解释换股并购
-

模拟山羊3骄傲军刀获取流程视频攻略|全球时讯
-

安邦集团董事_安邦集团相关内容简介介绍|视点
-

龚自珍代表作_龚自珍的代表作和简介
-

青海:端午假期全省接待游客88.38万人次
-

长和(00001)旗下和记港口与沙特能源园区设立合资公司 将独家营运SPARK物流设施
-
全球看点:异动快报:华建集团(600629)6月26日13点14分触及跌停板
-

百济神州直面专利侵权诉讼,来自海外“专业壁垒”的冲击有多大?|环球微资讯
-

德州市市长朱开国会见绿地张玉良:加快建设德州绿地创新谷 打造发展新引擎 快报
-

内爆“泰坦”号采用飞机过期碳纤维?波音公司回应
-

国家金融监督管理总局:今年以来银行业持续加大对重点领域和薄弱环节支持力度-快资讯
-

一碗米粉为何能上榜国家非遗?