什么是大模型? 世界今热点
2023-06-24 10:41:07 来源: 博客园
阅读本文之前,建议先阅读上一篇:什么是神经网络?
本文由gpt4辅助撰写(gptschools.cn)
什么是大模型?
模型是指具有大量参数的深度学习或机器学习模型,这些参数可以通过训练过程自动调整以捕获输入数据中的复杂关系。这类模型通常具有较深的网络结构和较多的神经元,以增加模型的表示能力和学习能力。大模型在诸如自然语言处理、计算机视觉和语音识别等领域取得了显著的成果。
 【资料图】
【资料图】
大模型使用了许多高级技术,主要包括以下几个方面:
- 深度神经网络(Deep Neural Networks,DNNs):大模型通常采用深度神经网络,拥有多个隐藏层,以捕捉输入数据中的高阶特征和抽象概念。
- 卷积神经网络(Convolutional Neural Networks,CNNs):在计算机视觉任务中,大模型通常采用卷积神经网络。通过局部感受野、权值共享和池化操作等设计,CNN可以有效处理图像数据,提取多尺度的视觉特征。
- 循环神经网络(Recurrent Neural Networks,RNNs)和长短时记忆网络(Long Short-Term Memory,LSTM):在序列数据处理任务(如自然语言处理和语音识别)中,大模型可能采用循环神经网络或其变体(如长短时记忆网络)来捕捉时序关系。
- Transformer 架构:Transformer 是一种自注意力机制(Self-Attention Mechanism)的神经网络架构,广泛应用于自然语言处理领域的大模型中。Transformer 可以并行处理输入序列中的所有元素,大幅提高了模型的训练效率。
- 预训练与微调(Pretraining and Fine-tuning):为了充分利用大量参数,大模型通常先在大规模数据集上进行预训练,学到通用的特征表示。然后,在特定任务的数据集上进行微调,以适应特定应用场景。
- 分布式训练(Distributed Training)和混合精度训练(Mixed Precision Training):为了处理大模型的计算和存储需求,研究者采用了一些高效训练策略,如分布式训练(将模型和数据分布在多个设备或节点上进行并行计算)和混合精度训练(利用不同精度的数值表示以减少计算和内存资源需求)。
这些技术和策略共同支持了大模型的开发和应用,使其在各种复杂任务中取得了出色的性能。然而,大模型也带来了训练成本、计算资源和数据隐私等方面的挑战。
什么是大模型的参数?
模型参数是指在机器学习和深度学习模型中可学习的权重和偏置等变量。在训练过程中,通过优化算法(如梯度下降)来调整这些参数,以最小化模型预测值与实际值之间的差距。参数的初始值通常是随机的,随着训练的进行,它们会逐渐收敛到合适的数值,以捕捉输入数据中的复杂模式与关系。
在大模型中,参数的数量通常非常庞大。举个例子,OpenAI的GPT-3模型拥有约1750亿个参数,使其能够执行更复杂的任务,如自然语言生成、翻译、摘要等。大量参数使模型具有更强的表示能力,但同时也带来了更高的计算成本和内存需求。这也是为什么大模型通常需要特殊的硬件资源(如GPU或TPU)和优化策略(如分布式训练和混合精度训练)来进行有效训练的原因。
以一个简单的深度学习模型为例:多层感知机(MLP,Multilayer Perceptron)。多层感知机是一种前馈神经网络,由输入层、若干隐藏层和输出层组成。每层都包含若干个神经元,相邻层之间的神经元通过权重矩阵相互连接。
假设我们的多层感知机有以下结构:
- 输入层:2个神经元(对应2个特征)
- 隐藏层:第一层3个神经元,第二层2个神经元
- 输出层:1个神经元
权重矩阵参数如下:
- 首先是输入层到第一隐藏层的权重矩阵,其形状为(2, 3),共有2 * 3 = 6个权重参数。
- 接着是第一隐藏层到第二隐藏层的权重矩阵,其形状为(3, 2),共有3 * 2 = 6个权重参数。
- 最后是第二隐藏层到输出层的权重矩阵,其形状为(2, 1),共有2 * 1 = 2个权重参数。
偏置参数如下:
- 第一隐藏层有3个神经元,因此有3个偏置参数。
- 第二隐藏层有2个神经元,因此有2个偏置参数。
- 输出层有1个神经元,因此有1个偏置参数。
将所有权重参数与偏置参数相加,该多层感知机共有6 + 6 + 2 + 3 + 2 + 1 = 20个参数。这是一个相对较小的模型。对于大模型,如GPT-3,参数数量可能达到数百亿,这使得它们能够表达更复杂的函数并执行更高级的任务。
大模型使用哪些并行训练方法?
大模型采用分布式训练方法来提高训练速度和扩展性。大体可以分为两类:数据并行与模型并行。
数据并行
数据并行(Data Parallelism):在这种方法中,模型分布在多个计算设备(如 GPU 或 TPU)上。每个设备都有模型的一个副本,但训练数据会被划分为不同的子集。每个设备使用其所分配的数据子集训练模型副本,然后通过通信协议(如 AllReduce 操作)同步梯度更新。
模型并行
模型并行(Model Parallelism):在模型并行中,模型被分割成多个部分,每个部分在单独的计算设备上运行。这种方法适用于无法放入单个设备内存的大型模型。当参数规模为千亿时,存储模型参数就需要数百GB的显存空间,超出单个GPU卡的显存容量。显然,仅靠数据并行无法满足超大规模模型训练对于显存的需求。为了解决这个问题,可以采用模型并行技术。在每个训练迭代中,设备间需要交换中间计算结果以完成前向和反向传播过程。模型并行从计算图的切分角度,可以分为以下几种:
流水线并行
流水线并行(Pipeline Parallelism):将模型的不同层划分到多个计算设备上,每个设备负责处理一部分模型层,即层间并行。在前向和反向传播过程中,设备之间需要传递中间计算结果。这种方法的优势是可以同时处理多个输入样本,从而提高计算设备的利用率。
张量并行
张量并行(Tensor Parallelism):将计算图中的层内的参数切分到不同设备,即层内并行,称之为张量模型并行。以一般的矩阵乘法为例,假设我们有 C = AB。我们可以将B沿着列分割成 [B0 B1 B2 ... Bn],每个设备持有一列。然后我们将 A 与每个设备上 B 中的每一列相乘,我们将得到 [AB0 AB1 AB2 ... ABn] 。此刻,每个设备仍然持有一部分的结果,例如,设备(rank=0)持有 AB0。为了确保结果的正确性,我们需要收集全部的结果,并沿列维串联张量。通过这种方式,我们能够将张量分布在设备上,同时确保计算流程保持正确。张量并行过程如下图所示:
并行训练使用的通信原语?
上述并行训练方法通常使用了以下通信原语:
数据并行-通信原语
- AllReduce:AllReduce 是一种将所有参与者的数据汇总起来并将结果广播回所有参与者的通信原语。在数据并行训练中,AllReduce 用于在计算设备之间同步权重梯度更新。常用的 AllReduce 实现有 NVIDIA NCCL、Intel MPI、OpenMPI 等。
- AllGather:AllGather 是将每个设备的数据收集在一起,并将结果发送到所有设备。这在某些数据并行任务中可能会用到,例如将不同设备产生的激活值或梯度拼接起来。
模型并行-通信原语
- Send/Recv 或 Point-to-Point Communication:这种原语用于在模型并行训练中将中间结果或梯度从一个设备传递到另一个设备。例如,在 Transformer 等自注意力机制的模型中,需要在计算设备之间传递中间张量。
- Collective Communication:这些原语(如 AllReduce、AllGather、Broadcast 等)也可能在模型并行中用到,例如在训练开始时同步模型参数或在训练过程中对某些梯度进行汇总。
- Send/Recv 或 Point-to-Point Communication:管道并行训练中,每个设备负责处理模型的一个部分,因此需要将中间结果(如激活值)传递给下一个设备。这通常通过 Send/Recv 或其他点对点通信原语来实现。
- Barrier:在管道并行中,某些情况下可能需要使用 Barrier 同步操作,以确保设备之间能够按顺序处理数据。这有助于避免死锁和数据不一致的问题。
AI Advisor 微信公众号
参考
- 猛猿:ChatGPT技术解析系列之:GPT1、GPT2与GPT3
- 常见的分布式并行策略
- 张量模型并行详解 | 深度学习分布式训练专题


热点推荐
-

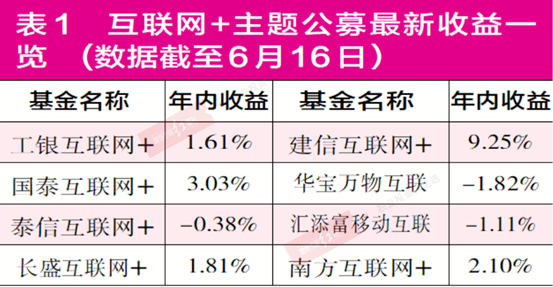
4月份淡水鱼价格同比上涨26.4% 环比上涨9.8%
-

郑州钢材市场扎堆儿京港线 京港线区域产业带崛起
-
嘉凯城(000918.SZ)今日起临时停牌 复牌时间未知
-
中证军工指数今日上涨3.96% 爱乐达涨17.36%
-
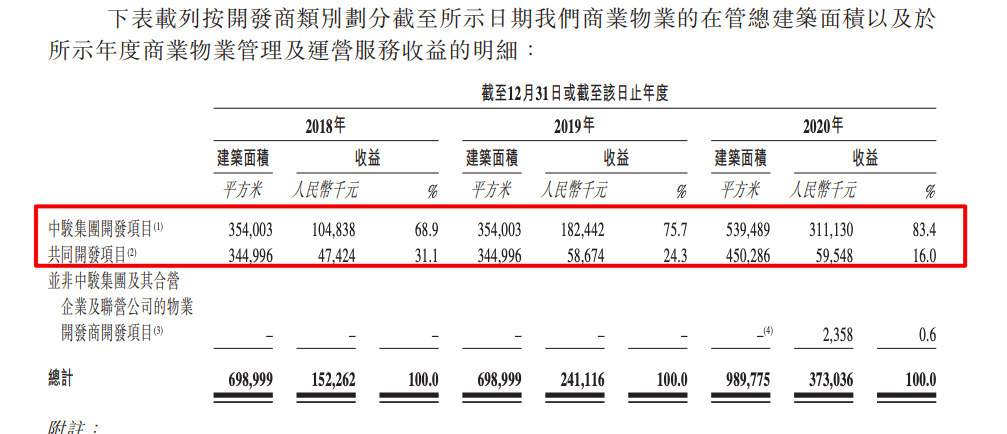
谷数科技谋求科创板IPO 拟募资5亿元
-
什么是大模型? 世界今热点
-

暴雨将至!请注意:限速!停航!
-

支付宝体验官发布通知:支付宝极小安装包测试任务已暂停
-

云南西盟:云雾绕山川 美景入画来
-

东丽区主题夜市点燃夏日活力 体验音乐美食盛会
-

被王晶发掘时还在读大二,拍3部电影狂捞26亿,成为最美晶女郎
-

今日中午12时起,陕西高考生可查成绩填志愿!_速读
-
焦点!突发!揭阳一龙舟侧翻致2人身亡,事故原因公布
-

2023年高考分数线汇总 来看看你那里是多少
-
每日资讯:山东日照:高温催热滨海旅游
-

宋永会
-

猝不及防和措不及防区别(猝不及防)-速看
-

热点评!正规平台手机兼职_正规靠谱的手机兼职
-

大乐透晒票23071期来了,你要成长,绝处也能逢生-世界消息
-

君子一言驷马难追的意思是(君子一言驷马难追的意思) 环球微头条
-

当前简讯:l1是什么线(L1,L2,L3代表什么线)
-

世界播报:恒大新能源汽车 知乎_恒大新能源汽车如何
-

留学生在境外遭绑架?“绑匪”索要500万元赎金 江城警方跨国联动76小时成功救人
-

日本全渔联向政府递交请愿书 ,重申反对核污染水排海
-

7月1日起青藏集团公司将实行新的列车运行图 将首次开行西宁进京、进沪G字头动车组列车
-

乱弹 | 分布式光伏,让农村媒婆月入十万?
-

全球微速讯:红烧牛肉最正宗的做法视频_红烧牛肉最正宗的做法
-

当前要闻:高考成绩今晚公布
-

普里戈任号召叛乱,已刑事立案!莫斯科加强安全措施
-

海安市星级养老院名单-天天快看点